Introduction and Objective
The main objective of this project was to develop and evaluate Machine Learning models for the prediction of Ischemic Cardiovascular Disease (ICD), using the well-known public "Heart Disease Dataset". The study aimed not only to reproduce the results of a reference K-Nearest Neighbors (KNN) model but also to investigate and compare its performance with more complex algorithms, such as Random Forest (RF) and Multilayer Perceptron (MLP).
Additionally, an ensemble model was built using the Stacking technique, which combines the predictions of the three individual algorithms to create a more robust and generalizable meta-model, aiming for performance gains and reliability in clinical diagnosis.
Methodology
The workflow was structured to ensure the robustness and reproducibility of the results, following best practices in data science:
Preprocessing and Exploratory Data Analysis:
An initial analysis of the dataset was conducted to identify feature distribution and the presence of outliers using descriptive statistics and boxplots.
Implausible values (such as cholesterol and resting blood pressure equal to zero) were treated as missing data. Extreme outliers in the
cholesterolfeature were removed using the 3x Interquartile Range (IQR) criterion to ensure a more robust model.The remaining zero values in the
cholesterolcolumn were imputed using the median, a measure of central tendency resistant to outliers.
Data Handling and Feature Scaling:
Numerical features were normalized using the
StandardScalerfrom the Scikit-learn library. This step is crucial for the performance of scale-sensitive algorithms like KNN and MLP.
Model Development and Comparison:
Three supervised classification algorithms were trained and evaluated:
K-Nearest Neighbors (KNN): An instance-based model, reproducing the approach of the original study.
Random Forest (RF): An ensemble model based on decision trees.
Multilayer Perceptron (MLP): A simple artificial neural network to investigate the viability of deep learning approaches.
Hyperparameter Optimization:
For each model, a rigorous hyperparameter optimization process was implemented using the
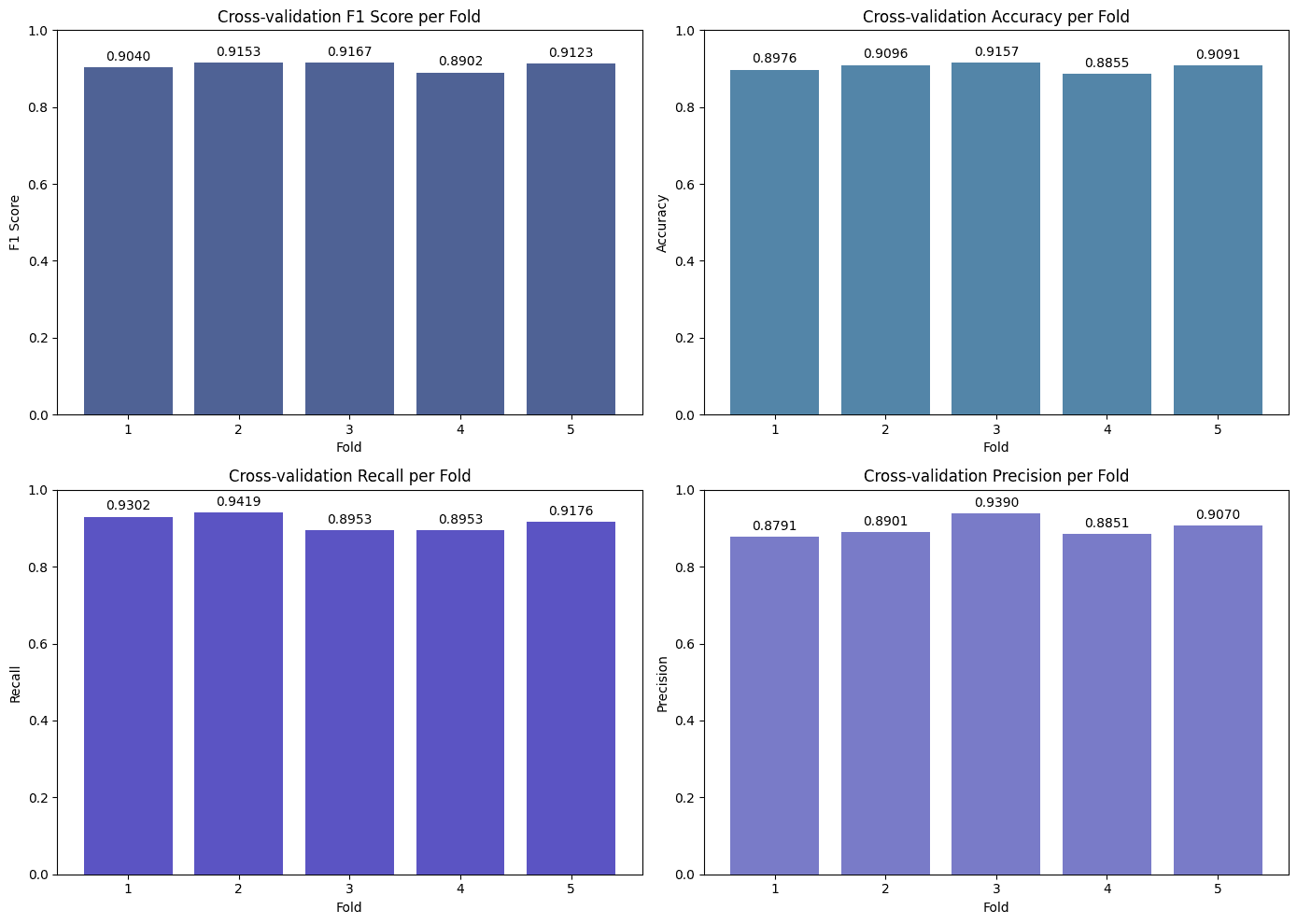
GridSearchCVtechnique.The primary metric for evaluating and selecting the best model was the F1-Score, due to its ability to balance Precision and Recall, which is critical in clinical contexts where both false positives and false negatives carry significant costs.
Ensemble Model Construction:
A
StackingClassifierwas implemented, using the optimized KNN, RF, and MLP models as base estimators and aLogisticRegressionas the meta-classifier (final estimator). The goal was to assess whether combining the strengths of different algorithms could lead to superior performance.
Tools and Technologies
Language: Python
Core Libraries:
Data Analysis & Manipulation: Pandas, NumPy
Machine Learning: Scikit-learn (for KNN, RF, MLP, Ensemble models,
GridSearchCV,StandardScaler, and evaluation metrics)Data Visualization: Matplotlib, Seaborn
Results and Analysis
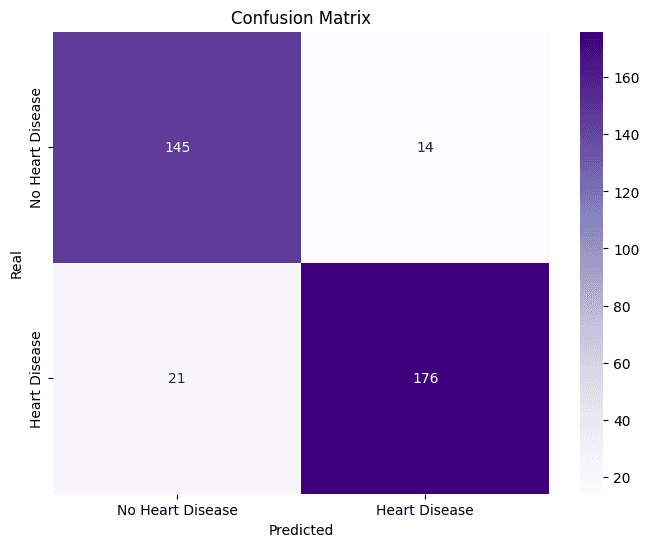
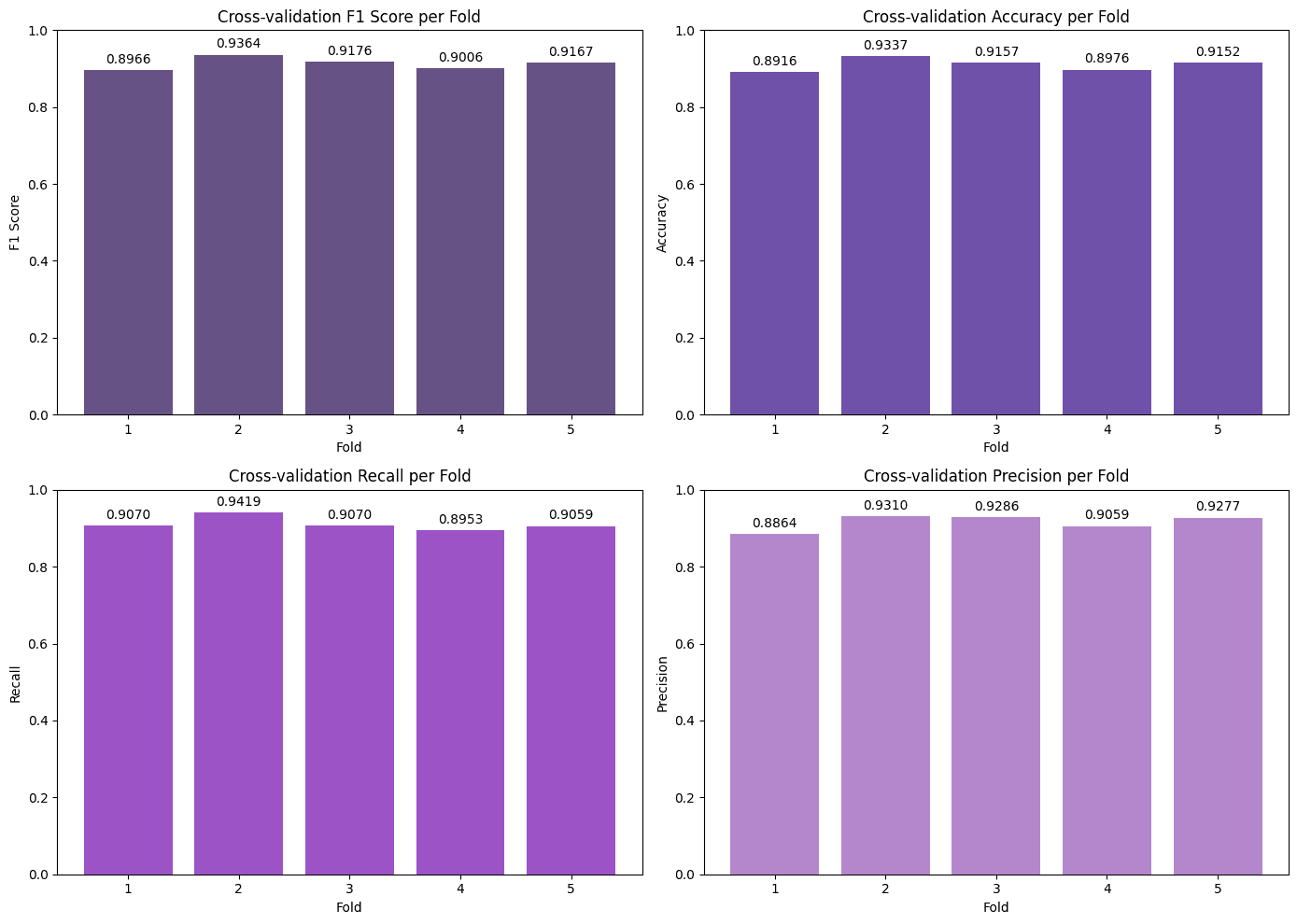
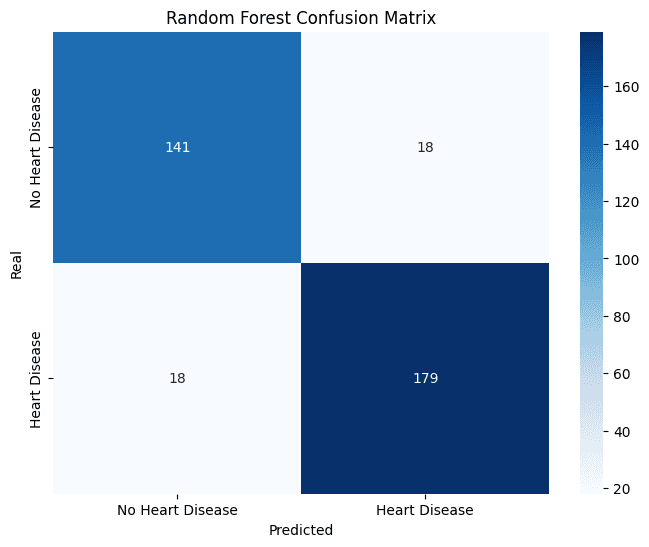
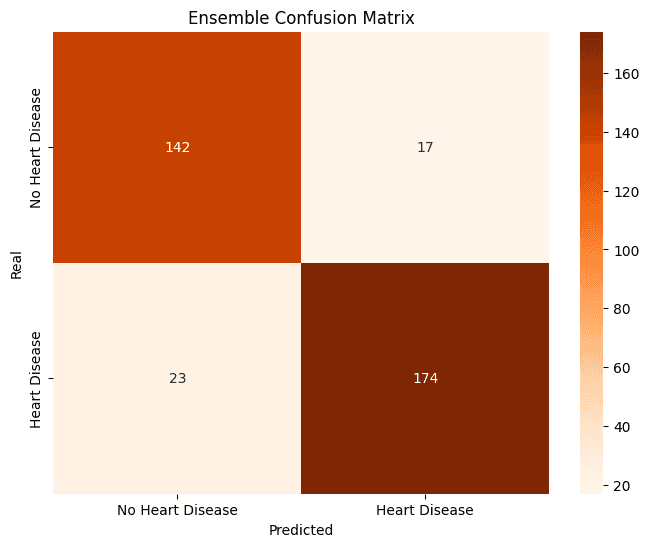
The KNN model, after hyperparameter optimization, demonstrated exceptional performance, achieving the highest F1-Score (0.91) and Accuracy (0.91) on the test set. The Random Forest showed very similar performance, standing out with the highest Recall (0.92), which indicates an excellent ability to correctly identify patients with ICD.
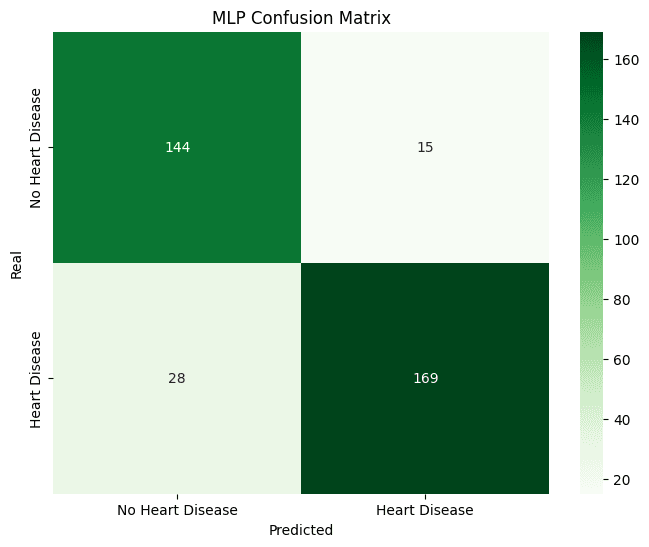
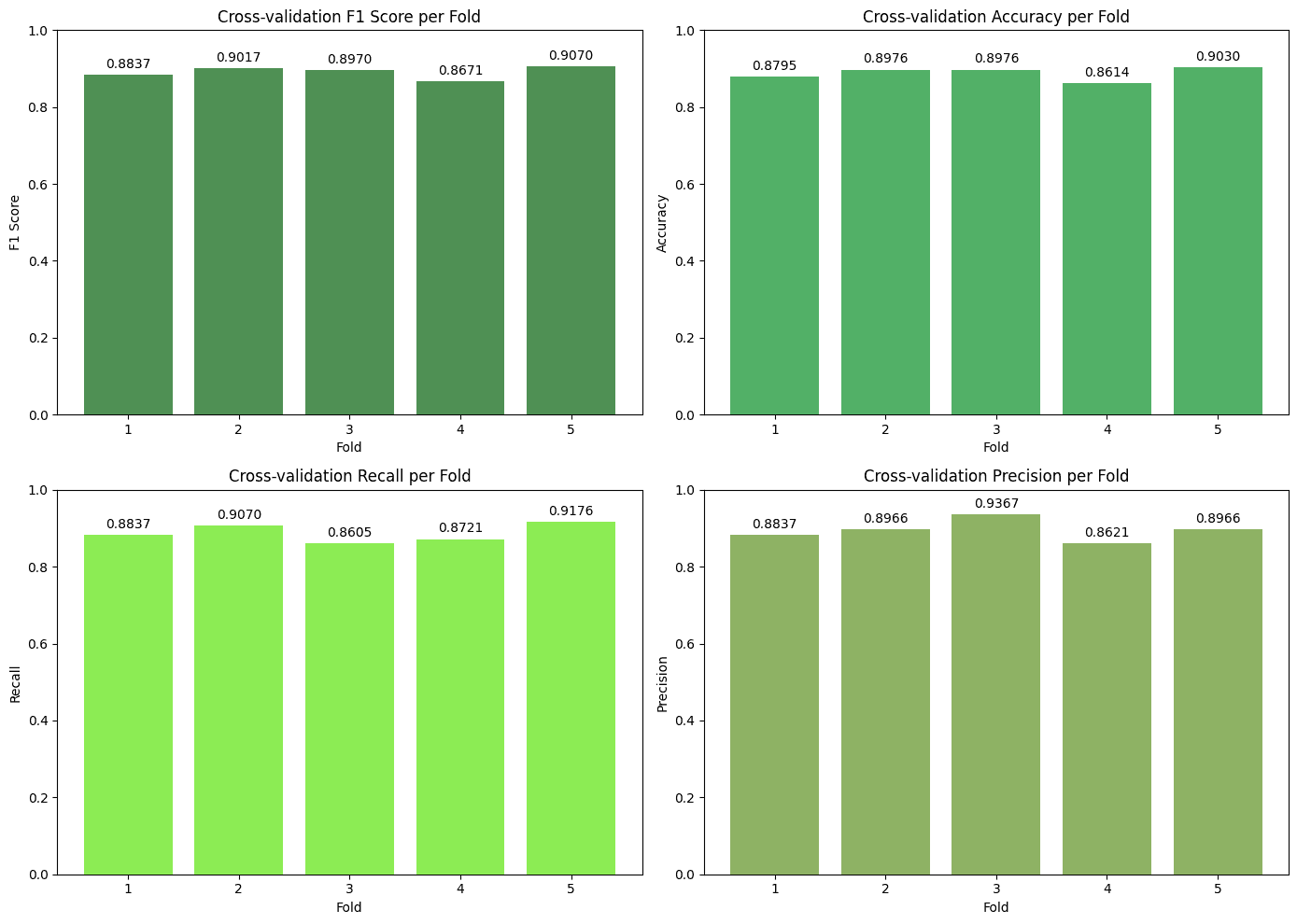
The Ensemble model, despite having the best F1-Score during cross-validation (0.918), performed slightly lower on the final test set but was still robust. The MLP, in turn, was the model with the most modest performance among the four, suggesting that for this dataset, more complex network architectures did not offer significant advantages over classic, well-tuned models.
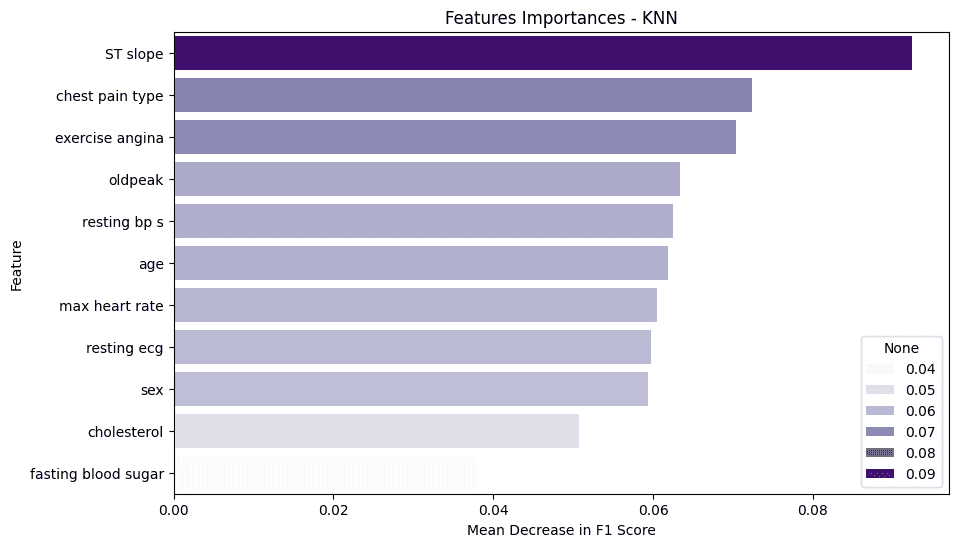
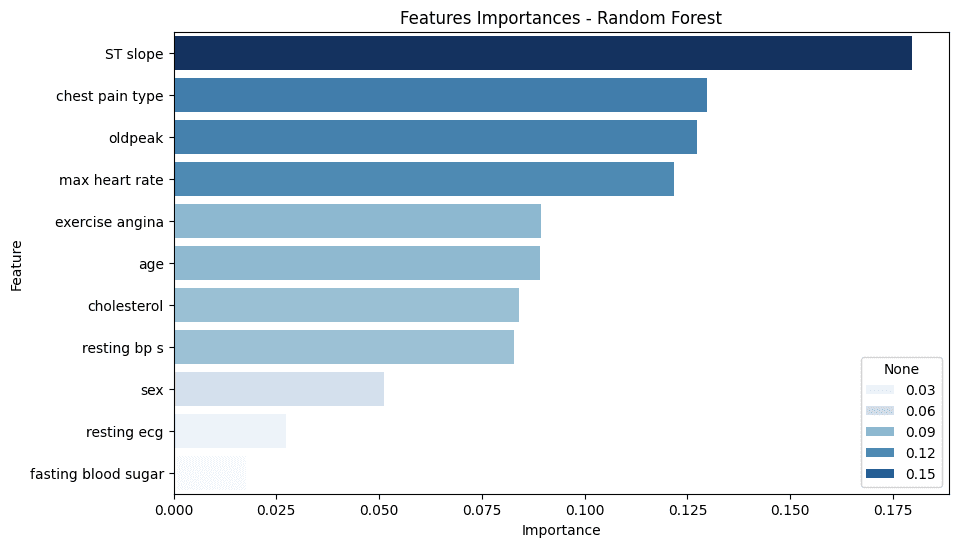
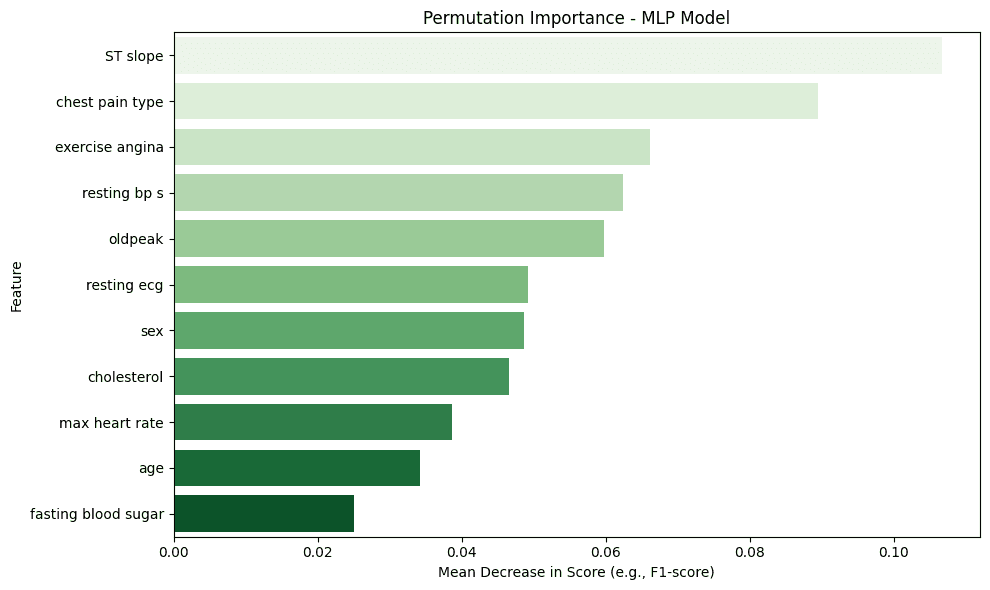
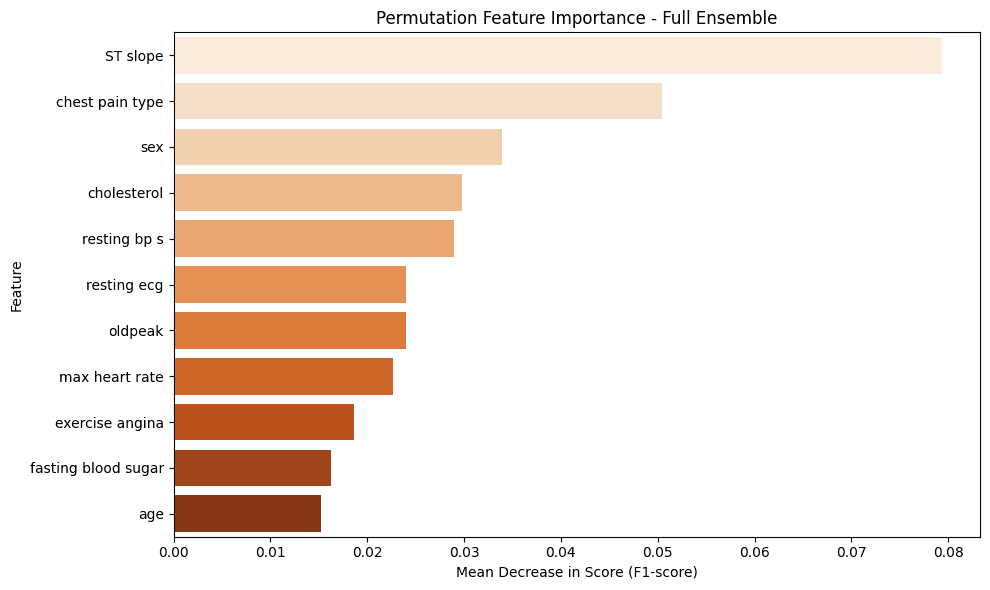
Feature Importance: The feature importance analysis, conducted using the Permutation Importance technique, revealed that the most predictive variables for diagnosing ICD were:
ST slope: The slope of the peak exercise ST segment on the electrocardiogram.
chest pain type: The type of chest pain reported by the patient.
exercise angina: The presence of exercise-induced angina.
Conclusion
This study demonstrated the high viability of using models like KNN and Random Forest for predicting Ischemic Cardiovascular Disease, achieving performance metrics above 90%. Successfully reproducing the KNN results validates the approach and reinforces the importance of careful preprocessing and hyperparameter optimization.
The investigation with the MLP and the Stacking ensemble provided valuable insights, showing that, in this scenario, more complex models do not necessarily guarantee superior performance compared to well-tuned classical algorithms. This project solidified my skills across the entire Machine Learning pipeline, from data cleaning and preparation to advanced modeling and, most importantly, the critical interpretation of results with a focus on clinical relevance.