Introduction and Objective
The main objective of this project is to analyze and classify indoor plants from a given dataset. The goal is to group plants based on relevant characteristics such as origin, climate, watering frequency, toxicity, and suitability for apartments. Through this, the project aims to create a classification system that can, for example, help users choose the ideal plant based on their experience level and availability for care.
Methodology
The project was divided into two main phases, executed in separate notebooks:
Preprocessing and Exploratory Data Analysis (
base.ipynb):Data Cleaning: The initial phase consisted of cleaning the
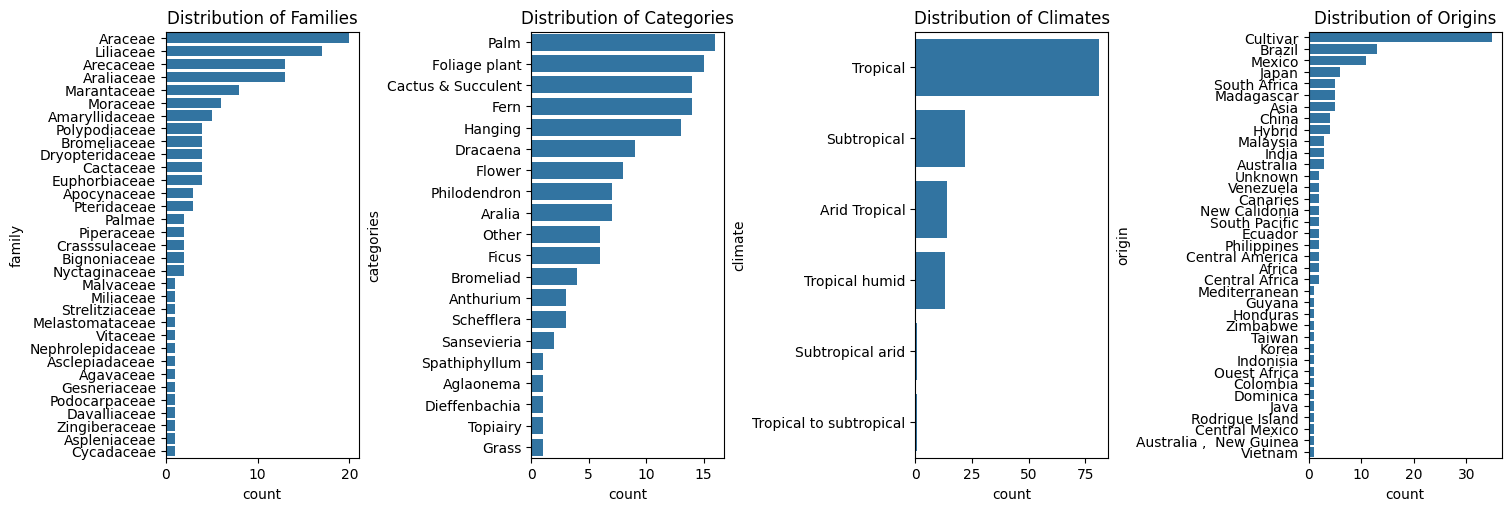
plants.csvdataset, which included removing duplicate data, handling missing values, and standardizing categorical information to ensure analytical consistency.Exploratory Data Analysis (EDA): Data visualizations were generated to understand the distribution and relationships between plant characteristics. Bar charts and other visual elements were used to analyze the frequency of plant families, categories, climates, and origins.
Feature Engineering: New columns (
features) were created to enrich the analysis. Attributes like soil type, sunlight, and watering frequency were transformed into numerical difficulty scales. Based on these scales, two high-level features were engineered:experience_level(Beginner, Amateur, Experienced) anddisponibility_level(Low, Medium, High).
Machine Learning Modeling (
model.ipynb):Clustering with K-Means: To complement the analysis, the K-Means clustering algorithm was applied. This unsupervised learning technique groups plants into distinct clusters based on their similarities.
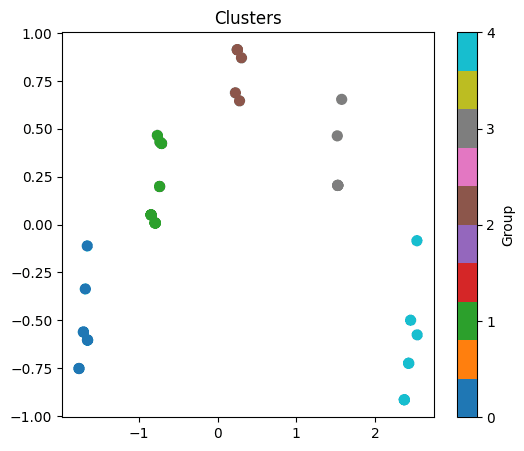
Determining the Number of Clusters: The "Elbow Method" was used to determine the optimal number of clusters, leading to the choice of k=5 clusters.
Cluster Visualization: Principal Component Analysis (PCA) was applied to reduce the dimensionality of the data, allowing the 5 clusters to be visualized in a 2D plot, which simplifies the interpretation of the formed groups.
Tools and Technologies
Programming Language: Python
Data Manipulation: Pandas and NumPy
Data Visualization: Matplotlib and Seaborn
Machine Learning: Scikit-learn (for implementing K-Means and PCA)
Results and Analysis
The initial exploratory analysis revealed important insights into the distribution of plants in the dataset. The feature engineering process enabled the creation of practical classifications (experience_level and disponibility_level) that add significant value. The application of the K-Means model resulted in the segmentation of the dataset into 5 distinct groups of plants. The visualization with PCA showed that these groups are well-defined, indicating that the model successfully identified relevant patterns in the plants' characteristics. These clusters can be used to create personalized recommendations.
Conclusion
This project successfully transformed a raw plant dataset into an organized and insightful resource. By cleaning the data, engineering meaningful features, and applying a K-Means clustering model, a practical framework for plant classification was created. The resulting 5 clusters provide a solid foundation for developing a recommendation system that can guide users to the plants best suited for their environment and experience level.
Future work could involve deploying this model as a simple web application or API, allowing users to input their preferences and receive plant suggestions. Additionally, the model could be enhanced by incorporating more data, such as pest resistance or air-purifying qualities, and by exploring alternative machine learning models to further refine the classifications.